Best Fuel Price Near You
The idea of this project was to develop a program that uses genetic algorithm to search the best gas station for the user from a list of existing data in the program database. In brief, the program asks the user for their location to evaluate gas stations based on distance and gas price. At the end of the search, the program returns the rank found with the best result in the evaluation function, its position and the price of fuel.
More specifically, the database was created containing information on 1000 gas stations. Each index in the database contained the index, the price of gasoline, the price of alcohol, the X position and the Y position of the station. These data were generated at random and only maximum and minimum limits were set for each value. The data was eventually converted to JSON (JavaScript Object Notation) format to easy understanding by the program.
The program starts by reading the database and initializing the parameters of the genetic algorithm. Specifically, population size (N), number of generations (X), mutation factor (M), and number of elites (E) are initialized.
After the user has determined the search targets, ie their location and fuel type, the algorithm begins by randomly choosing N ranks to make up the initial population. The Population vector contains the indexes of the selected stations only, since the database is always available and the operation of obtaining a value from it, knowing its location, has minimal complexity.
All members of the population are then judged on their fitness, in other words, the characteristics of the gas stations go through the evaluation function in order to generate a value that determines how good this data would be for the user. These values are stored in the fitness vector of size N; thus the first term of Aptitude refers to the quality of the gas station whose index is recorded in the first position of the Population vector, the second term is the aptitude of the gas station in the second Population position and so on.
Knowing the fitness of each gas station, the selection is made. The method chosen was Roulette, which selects an data randomly but tends to those with better fitness. The select function choose two fathers and calls the reproduction function, which returns two sons from a weighted average of the two fathers indexes. This process is repeated N/2 times, so that the final one has N sons, which are stored in a NewGeneration vector.
Next, all NewGeneration members are individually tested to decide whether or not to mutate. The chance of mutation is M% for all. If there is a mutation, a random number up to 100 is added to the gas station index. If, after the sum, the index would exceed the database limit, this number is subtracted instead.
Finally, E random data in NewGeneration are selected and replaced by the E best performing in the Population. After this last NewGeneration update, its value is assigned to Population. This was just a generation, and the process is repeated X times.
At the end of the X generations, the Population vector is traversed and the algorithm returns the Population individual with the best Fitness value, along with their respective coordinates (X, Y) and the chosen fuel price.
Here is website result:
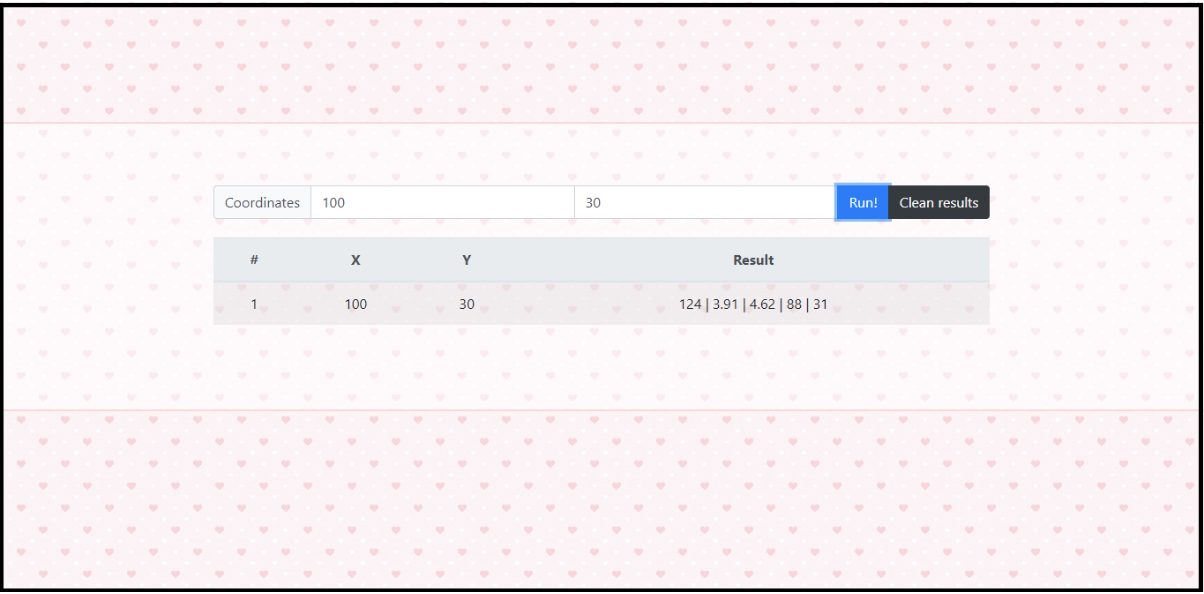
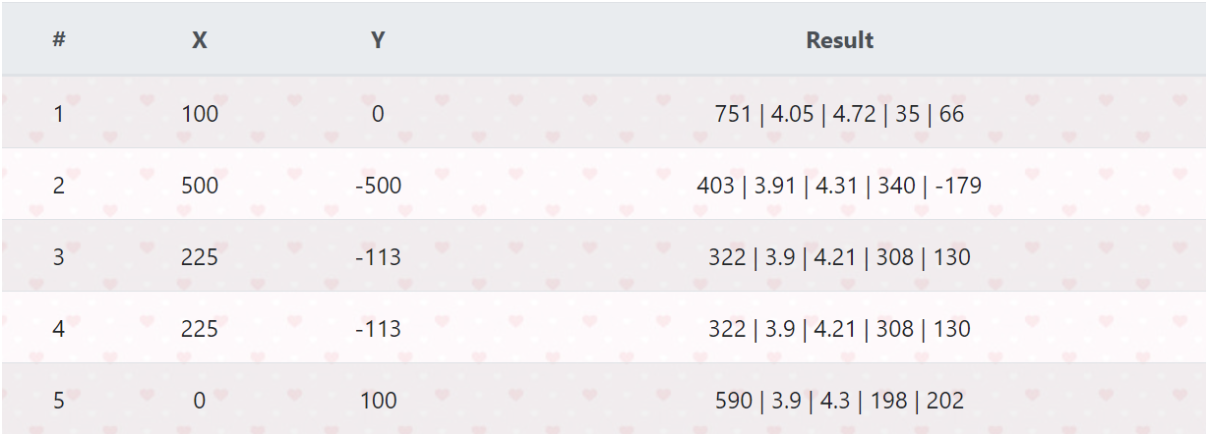
As you can see there are two spaces, which the user says his/her/them position in X and Y and after clicks in “Run!” bottom to initialize the program. The answer is: the first data is the index about how many times was said the info, the second data is the X, the third is Y. Next, the result shows as the first data the index of best gas station on database for the case, the second data as price of the gasoline in this gas station, the third data as price of alcohol in the gas station, and the end data as X and Y of this gas station.
Would you like to see the code? Go ahead.